Round Egg 7: Compute shaders - GPU queues
written by druskus
on the
1st of November 2023
Last time we explored how to manually initialize and run a compute shader, however, it once again became evident how much effort working directly with wgpu code was going to be. In an attempt to simplify our iteration process, we switched to a compute shader library. We found the one reasonable option to be bevy_app_compute .
Update: Recently, an alternative library that seems better maintained has come up. It might be worth a shot. For the moment we are not thinking of migrating to it.
An important limitation of most platforms is the existence of a single command
queue. To my knowledge it is only the latest platforms that allow multiple
ones (Directx12 and Vulkan). wgpu however, does not yet support this feature.
The current implementation of wgpu only has one interal queue for submit() calls. Therefore, we still have to know where and when to put our compute submit() calls, as they will run sequentially with the render queue. I know that vulkan has a separate compute queue, and I'm hoping that one day, wgpu will too. I just don't know how feasible / mature this multi-queue system is for other backends wgpu implements.
This means that we cannot run our compute shader without blocking the render queue. This is not a big deal for us, since we only want to run our compute job once, at the beginning of the program.
#
A small dive into submit calls and GPU queues
Let's explore a bit deeper into the nature of submit calls and GPU queues:
This article
does a good job at explaining the difference between asynchronous workload
submission and parallel workload processing.
-
"Asynchronous workload submission is the encompasses the ability for the CPU host side to be able to do other work whilst the GPU is processing the workload."
-
"Parallel workload processing consists of the concurrent execution of two or more workloads by the GPU."
Latest GPUs have several "queue families" (this is Vulkan's naming convention), each with a different purpose (graphics, compute, transfer). Each queue family can have one or more queues.
For example, I believe an NVIDIA 1650 card has 3 queue families:
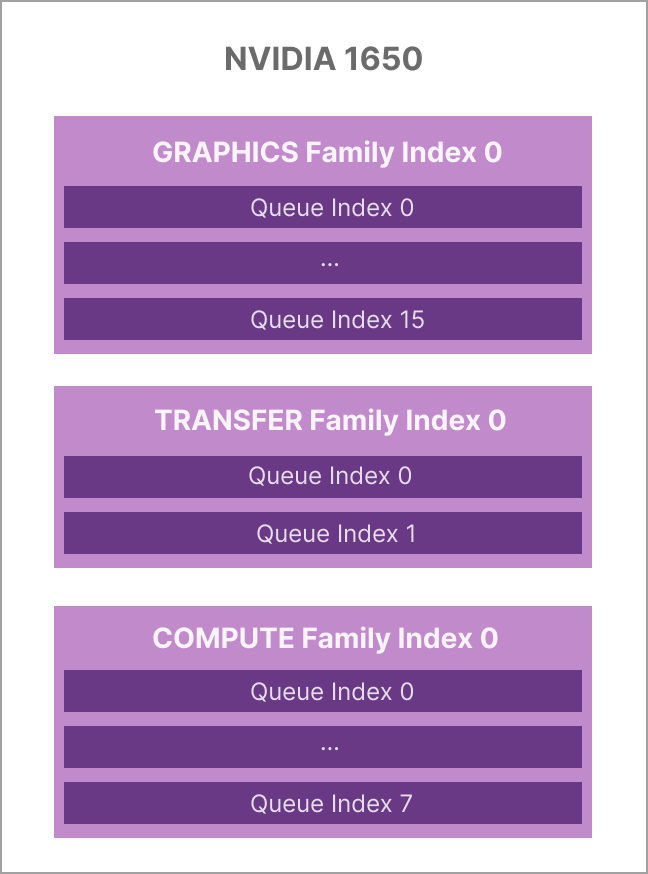
We can actually see check the capabilities of each queue:
Queue family #0 supports transfer, graphics, compute, and presentation
Queue family #1 supports only transfer, and nothing else
Queue family #2 supports transfer, compute, and presentation
Intra-queue parallelization is not supported at the moment, which means that we would in any case only be able to run one type of workload at a time on a single queue.
Any task you throw into a queue will attempt to use 100% of the available hardware to finish, however you can generally have one compute task and one graphics task running side by side, as the two are usually separate from each other.
Furthermore, queues (at least in Vulkan), are distinguishable, they can be indexed and can have different priorities. This might be useful when submitting different types of workloads, as a hint to the Vulkan implementation on which tasks you would like to favour.
# Difference between Vulkan and DirectX 12
D3D12 has the same separation between compute pipelines and graphics pipelines that Vulkan does. However, when issuing commands, D3D12 has only one pipeline binding point, to which you can bind any kind of pipeline. By contrast, Vulkan has separate binding points for compute and graphics pipelines. Of course, Vulkan doesn't have different descriptor binding points for them, so the two pipelines can interfere with one another. But if you design their resource usage carefully, it is possible to invoke a dispatch operation without disturbing the needs of the graphics pipeline.
So overall, there's no real difference in pipeline architecture here.
# Wrapping up
We recommend reading through these two Github issues if interested:
- Bevy's Issue 8440 : To get a better understanding on Bevy's renderer architecture.
- Bevy's Issue 5024 : Discussion on separating the render and compute queues. Note that some of the stuff suggested regarding Unity does not appear to be accurate. I do not believe that Unity automatically split compute tasks into smaller pieces.
For our case, wgpu's single queue limitation was not a problem - mostly since we are using compute shaders
for fun and since our implementation will only require to run the compute
shader on initialization. In the next post we will explain how web ran our
sphere deformation shader with
bevy_app_compute
.